이번 시간에는 이어서 셀레니움을 통해 크롤링 하는 방법을 알아보겠습니다.
셀레니움 준비하기
먼저 셀레니움을 쓰기 위해서는 크롬 드라이버를 다운받아야 합니다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 106, please download ChromeDriver 106.0.5249.21 If you are using Chrome version 105, please download ChromeDriver 105.0.5195.52 If you are using Chrome version 104, please download ChromeDriver 104.0.5112.79
chromedriver.chromium.org

이 때 크롬 버전 확인이 필요한데요.
주소창에서 settings를 치면 크롬 버전을 알 수 있습니다.
chrome://settings/help
제 버전은 104이니 크롬 드라이버 역시 104버전을 다운로드 받습니다.

저는 윈도우에서 사용하기 때문에 윈도우 32버전을 다운로드 받습니다.

그리고 selenium을 설치해줍니다.
pip install selenium

이 후
import time
from selenium import webdriver
browser = webdriver.Chrome('C:\python/chromedriver.exe') # "./chromedriver.exe"
# 1. 네이버 이동
browser.get("http://naver.com")이렇게 하면 자동으로 네이버 사이트에 이동하는 것을 알 수 있습니다.
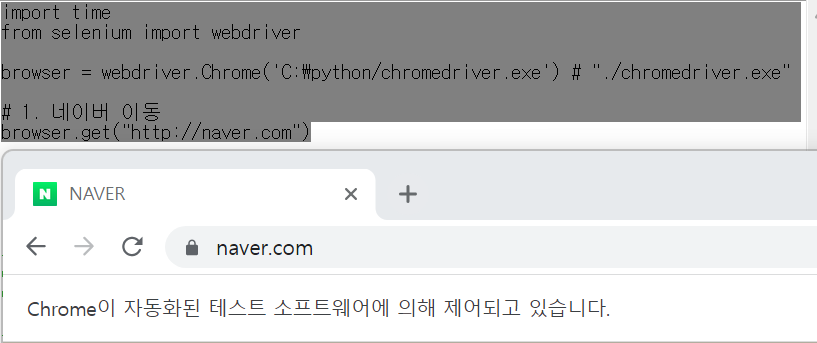
나도 코딩 셀레니움 에러 해결
그리고 나도 코딩과 같이 실행을 했더니 셀레니움 버전이 달라 아래의 에러가 뜹니다.
selenium AttributeError 'Webdriver' object has no attribute 'find_element_by
즉 셀레니움이 3에서 4로 버전업 되면서 문법이 변경되었는데요.
이제 from selenium.webdriver.common.by import By
By 패키지를 불러와야 하고 그리고 문법 역시 find_element로 변경되었습니다.
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome('C:\python/chromedriver.exe') # "./chromedriver.exe"
# 1. 네이버 이동
browser.get("http://naver.com")
# 2. 로그인 버튼 클릭
#elem = browser.find_element_by_class_name("link_login")
elem = browser.find_element(By.CLASS_NAME, "link_login")
elem.click()그리고 각각의 용법은 아래와 같고 불러올때
find/find_all처럼 find_element는 하나만 find_elements는 여러개를 불러옵니다.
| By.ID | 태그의 id값으로 추출 |
| By.NAME | 태그의 name값으로 추출 |
| By.XPATH | 태그의 경로로 추출 |
| By.LINK_TEXT | 링크 텍스트값으로 추출 |
| By.PARTIAL_LINK_TEXT | 링크 텍스트의 자식 텍스트 값을 추출 |
| By.TAG_NAME | 태그 이름으로 추출 |
| By.CLASS_NAME | 태그의 클래스명으로 추출 |
| By.CSS_SELECTOR | css선택자로 추출 |
그렇게 해서 아래의 아이디 입력칸도 변경된 문법으로 만들어 줍니다.
browser.find_element(By.ID, "id").send_keys('naver_id')그리고 프로그램을 실행해보면 아래처럼 자동으로 네이버 아이디까지 입력하는 것을 확인할 수 있습니다.

이렇게 셀레니움을 통해서도 간단하게 네이버 자동 로그인을 하는 방법을 알아보았는데요.
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome('C:\python\chromedriver.exe') # "./chromedriver.exe"
# 1. 네이버 이동
browser.get("http://naver.com")
# 2. 로그인 버튼 클릭
#elem = browser.find_element_by_class_name("link_login")
elem = browser.find_element(By.CLASS_NAME, "link_login")
elem.click()
browser.find_element(By.ID, "id").send_keys('naver_id')
browser.find_element(By.ID, "pw").send_keys("password")
browser.find_element(By.ID, "log.login").click()
time.sleep(3)이렇게 간단히 사용할 수 있으니, 잘 사용해보시기 바랍니다.
그리고 더 자세한 내용은 차차 하나씩 알아보도록 하겠습니다.
'Programming > Python' 카테고리의 다른 글
| 파이썬 웹사이트 크롤링하기 - 5. Selenium headless (0) | 2022.08.30 |
|---|---|
| 파이썬 판다스 SettingWithCopyWarning 에러 해결하기 (0) | 2022.08.29 |
| 파이썬 웹사이트 크롤링하기 - 3.BeautifulSoup/find함수로 찾기 (0) | 2022.08.26 |
| 파이썬 웹사이트 크롤링하기- 2. 오늘날씨 가져오기 (0) | 2022.08.23 |
| 파이썬 웹사이트 크롤링하기- 1. request (0) | 2022.08.22 |