


파이썬을 활용해서 웹사이트 크롤링을 이어서 해보겠습니다.
이제 request로 파일을 찾아오면 Beautifulsoup을 활용해서 크롤링한 파일을 정리하는데요.
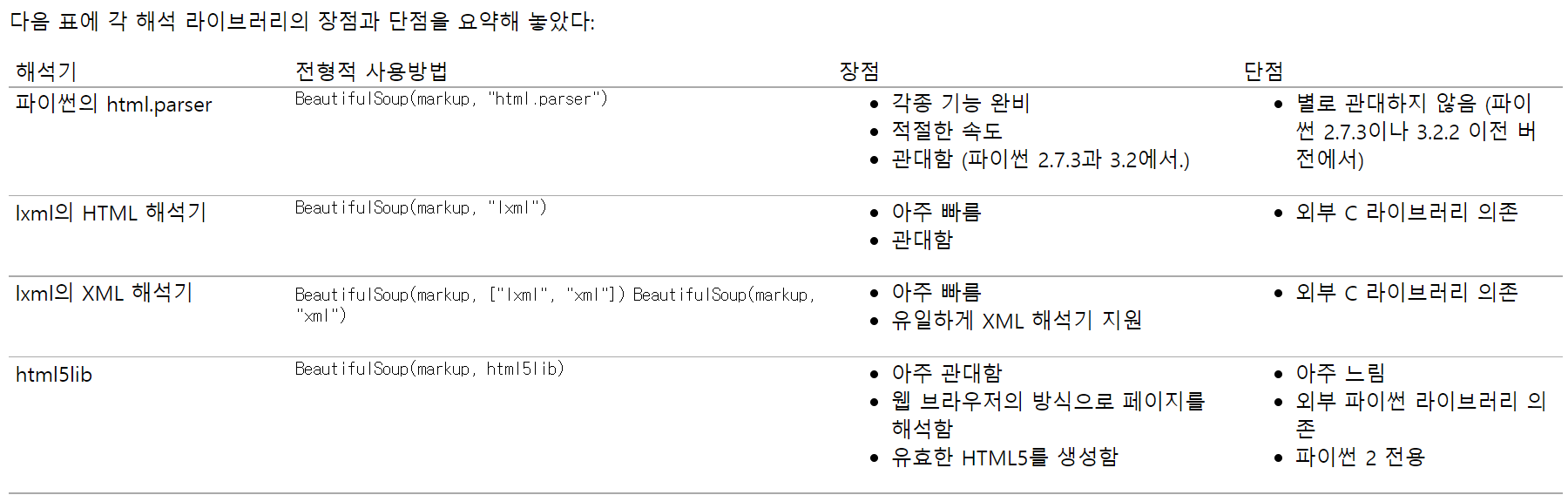
BeautifulSoup이란?
BeautifulSoup는 HTML과 XML 파일로부터 데이터를 뽑아내기 위한 파이썬 라이브러리이다.
여러분이 선호하는 해석기와 함께 사용하여 일반적인 방식으로 해석 트리를 항해, 검색, 변경할 수 있다.
한글 도큐먼트는 링크에서 확인이 가능합니다.
뷰티플수프 문서 — 뷰티플수프 4.0.0 문서
find_all() 메쏘드는 태그의 후손들을 찾아서 지정한 여과기에 부합하면 모두 추출한다. 몇 가지 여과기에서 예제들을 제시했지만, 여기에 몇 가지 더 보여주겠다: 어떤 것은 익숙하지만, 다른 것
www.crummy.com
이 때 해석 라이브러리를 선택할 수 있는데요.
html.parser 또는 lxml을 주로 사용합니다.
이 후 이렇게 분석된 파일에서 우리가 원하는 파일을 찾기 위해서 트리해석이라는 과정을 거치는데요.
일반적으로 이때 사용하는 함수는 find()와 find_all()입니다.
find는 원하는 값을 하나만 찾아주고 find_all은 모든 값을 찾아줍니다.이때 정규 표현식을 활용하면 더 효율적으로 원하는 값을 찾을 수 있습니다.
그래서 나도코딩 강의에서 살펴보면 아래의 코드를 살펴볼 수 잇는데요.
각각 함수를 뜯어보면 res라는 변수에 requests.get을 통해서 url과 헤더 정보를 넣어줍니다.
헤더가 없을 경우 사이트에서 차단할 수 있기 때문이죠.
그리고 raise_for_status를 통해서 에러나면 탈출할수 있게 하구요.
뒤에는 res.text값에 대해서 lxml 해석기로 해석해서 soup라는 변수에 넣었습니다.
그리고 마지막에 find_all과 함께 정규 표현식 re.compile을 통해서 search-product로 시작하는 li class를 모두 찾아옵니다.
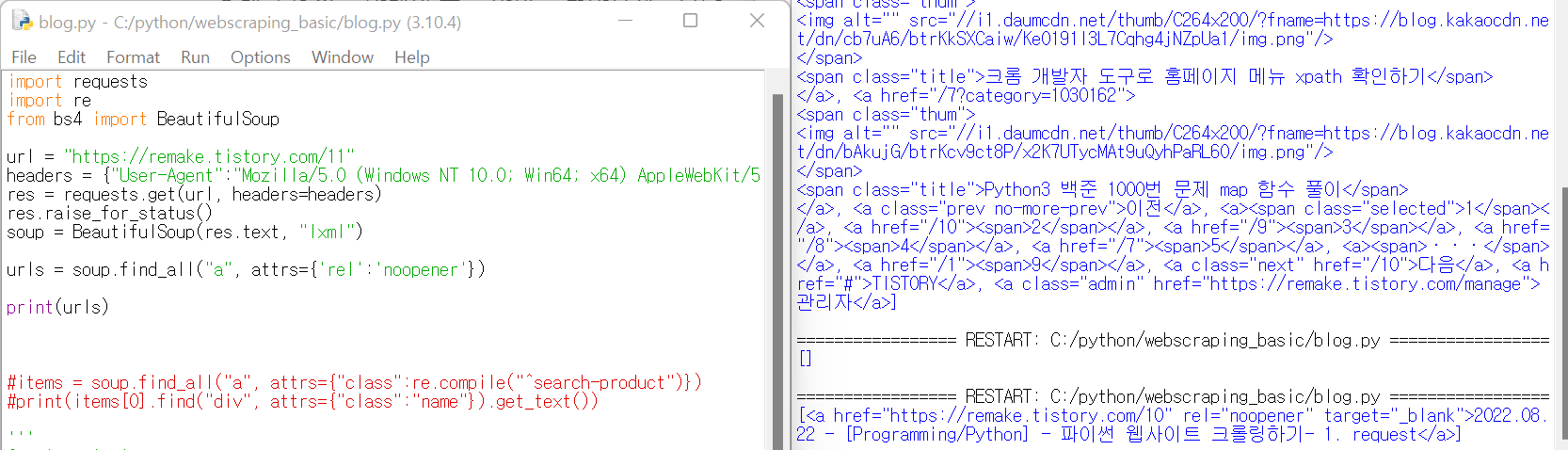
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":re.compile("^search-product")})여기까지가 아주 기초적인 파이썬의 원하는 값 찾기 인데요.
실제로 제 블로그에서 한번 찾아보겠습니다.
a 태그가 있는 아래의 글을 한번 불러와보겠습니다.
저번 2편에서처럼 크롬 개발자 도구를 통해서 해당 위치를 찾아보고
<a> 태그에 rel이라는 특성이 noopener라는 것을 확인하였습니다.

단순히 find_all에 a 태그만 찾았더니 너무 많이 나왔는데요.
뒤에 특성을 rel : noopener를 주니 딱 하나만 잘 찾아왔습니다.
이렇게 전체 페이지에서 원하는 값을 찾아오는 것을 연습해보았는데요.
정말 간단하게 페이지에서 내가 원하는 것을 찾을 수 있었습니다.
이런 방법을 활용해서 웹페이지를 크롤링하시면 됩니다.
그럼 즐거운 하루 보내세요.
'Programming > Python' 카테고리의 다른 글
| 파이썬 판다스 SettingWithCopyWarning 에러 해결하기 (0) | 2022.08.29 |
|---|---|
| 파이썬 웹사이트 크롤링 하기 - 4. Selenium 사용하기 (1) | 2022.08.27 |
| 파이썬 웹사이트 크롤링하기- 2. 오늘날씨 가져오기 (0) | 2022.08.23 |
| 파이썬 웹사이트 크롤링하기- 1. request (0) | 2022.08.22 |
| 크롬 개발자 도구로 홈페이지 메뉴 xpath 확인하기 (1) | 2022.08.22 |