

1번편에 이어서 오늘날씨 크롤링을 한번 따라해보겠습니다.
2022.08.22 - [Programming/Python] - 파이썬 웹사이트 크롤링하기- 1. request
나도코딩 홈페이지에 있는 샘플이 네이버 페이지가 개편되면서 일부 맞지 않는 항목이 있어서 수정해보았습니다.
서울 날씨로 검색했을때 아래와 같이 검색 결과가 나옵니다.

프로그램을 실행시키면 처음부터 에러가 나는데요.
이유가 현재 날씨 표시방식이 달라졌습니다.
현재 온도가 태그를 보면

현재온도는 span의 class: blind 태그에서 찾을 수 있구요.

그리고 어제랑 비교는 이렇게 span에 temperature.up과 temperature.down이라는 두개의 함수에 나눠서 있습니다.
즉 이 경우에 둘 케이스에 대해서 예외처리를 해줘야 하는데요.
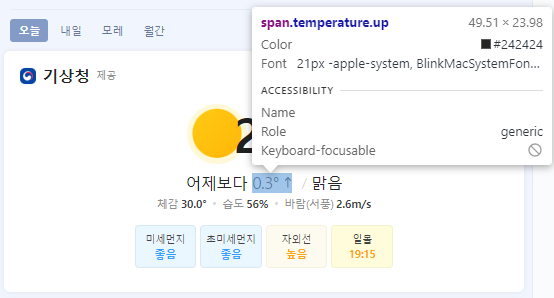
저의 경우 try: except를 통해서 2번 확인하는 것으로 변경해보았습니다.
try:
cast = soup.find("span", attrs={"class":"temperature down"}).get_text()
except:
cast = soup.find("span", attrs={"class":"temperature up"}).get_text()그리고 강수확률의 경우에도
span의 rainfall에 위치하고 있는데요. 모두 다 같은 태그로 묶여 있음을 알 수 있습니다.

그래서 부득이하게 함수를 일부 변경하여
첫번째는 오전으로 2번째는 오후 강수확률로 설정하였습니다.
morning_rain_rate = soup.find_all("span", attrs={"class":"rainfall"})[0].get_text().strip() #오전강수확률
afternoon_rain_rate = soup.find_all("span", attrs={"class":"rainfall"})[1].get_text().strip() # 오후 강수확률미세 먼저 역시 변경되어 숫자가 아닌 좋음 나쁨으로만 표기되기 때문에
이부분도 간단하게 변경하였습니다.
pm10 = soup.find_all("span", attrs={"class":"txt"})[0].get_text() # 미세먼지
pm25 = soup.find_all("span", attrs={"class":"txt"})[1].get_text() # 초미세먼지여기까지 진행하면 오늘의 날씨 부분은 정상적으로 동작하는 부분은 아래와 같습니다

현재 온도의 경우 strong 함수 아래에 있어서 모두 찾고
10번째 값을 가져왔습니다.
curr_te = soup.find_all("strong")
curr_temp = curr_te[10].get_text()[3:]select를 이용하는 방법도 있는데요.
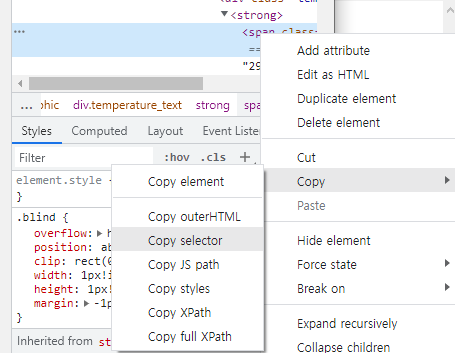
이 때 개발자도구에서 css selector를 하면 nth-child(1)가 되어 에러가 뜨므로 이를 nth-of-type(1)로 변경해줘야 합니다.
curr_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div._tab_flicking > div.content_wrap > div.open > div:nth-of-type(1) > div > div.weather_info > div > div._today > div.weather_graphic > div.temperature_text > strong').text이렇게 간단하게 프로젝트 소스를 일부 수정해보았습니다.
감사합니다.
'Programming > Python' 카테고리의 다른 글
| 파이썬 웹사이트 크롤링 하기 - 4. Selenium 사용하기 (1) | 2022.08.27 |
|---|---|
| 파이썬 웹사이트 크롤링하기 - 3.BeautifulSoup/find함수로 찾기 (0) | 2022.08.26 |
| 파이썬 웹사이트 크롤링하기- 1. request (0) | 2022.08.22 |
| 크롬 개발자 도구로 홈페이지 메뉴 xpath 확인하기 (1) | 2022.08.22 |
| Python3 백준 1000번 문제 map 함수 풀이 (1) | 2022.08.21 |