네이버는 다양한 API를 제공하는데요. 오늘은 네이버 뉴스 API를 사용하는 방법을 알아보겠습니다.
네이버 뉴스 API
네이버의 다양한 API는 네이버 developers에서 확인이 가능한데요.

새로 만들려면 애플리케이션 등록에서 하면 됩니다.
🛠️ 네이버 개발자 센터 등록 및 애플리케이션 생성
API를 사용하려면 먼저 네이버 개발자 계정을 만들고, 내가 만들 서비스(애플리케이션)를 등록해 자격 증명(Key)을 발급받아야 합니다.
- 네이버 개발자 센터 접속 및 로그인
- 네이버 개발자 센터에 접속하여 네이버 계정으로 로그인합니다.
- 애플리케이션 등록
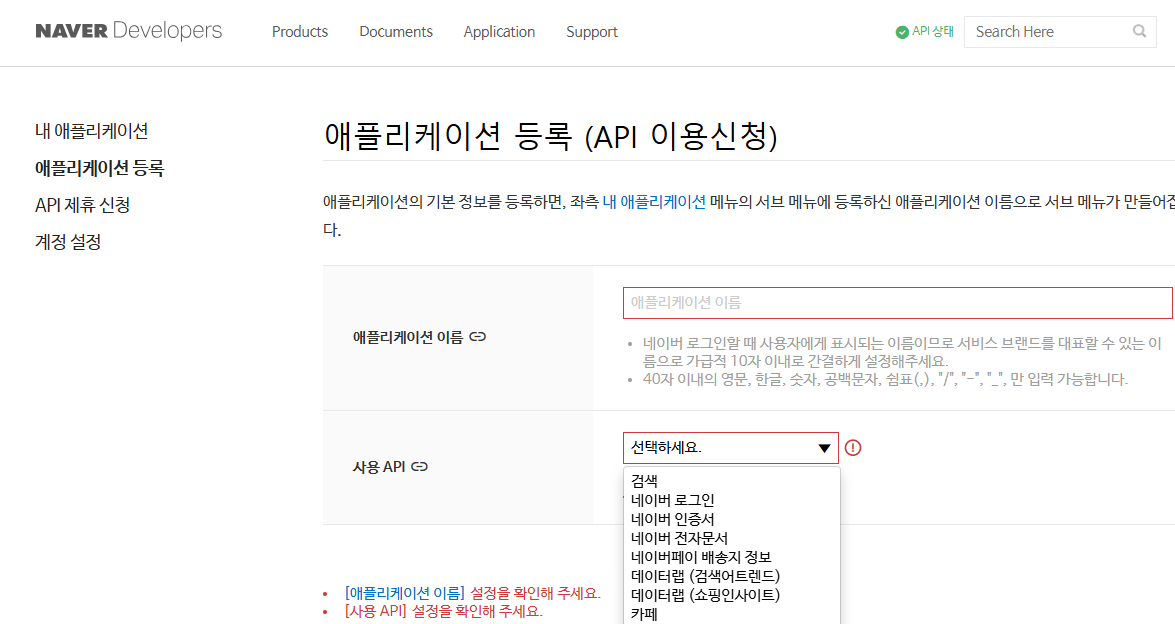
- 상단 메뉴에서 [Application] -> [애플리케이션 등록]을 선택합니다.
- 정보 입력
- 애플리케이션 이름: 원하는 이름 입력 (예: MyWebProject)
- 사용 API: 내가 사용할 API 선택 (예: 검색, 네이버 로그인, Papago 번역 등)
- 로그인 오픈 API 서비스 환경: API를 사용할 환경 선택 (예: WEB, Android, iOS 등)
- 수신 URL (웹 기준): 서비스를 제공할 도메인 주소 입력 (로컬 테스트용이라면 http://localhost 또는 http://127.0.0.1 입력 가능)
- 등록 완료 및 Key 확인
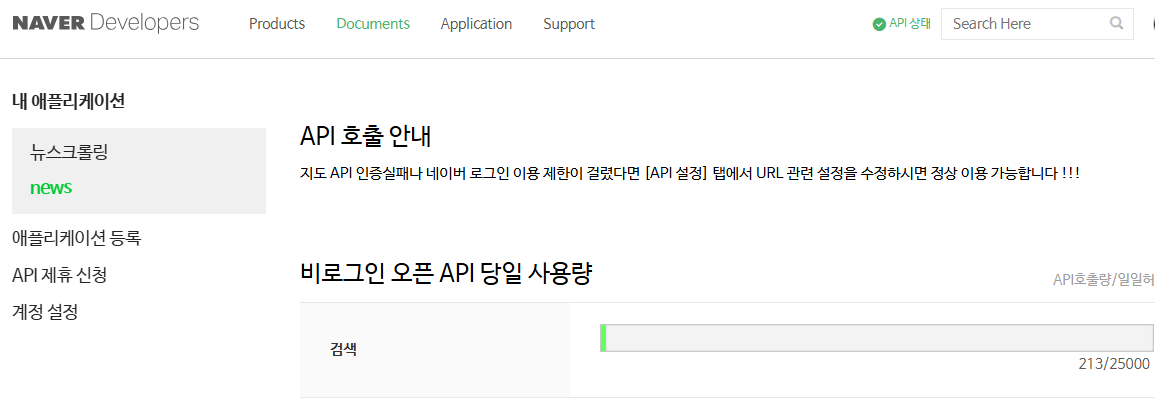
- 등록을 마치면 [Application] -> [내 애플리케이션]에서 등록한 프로젝트를 확인할 수 있습니다.
- 여기서 가장 중요한 Client ID와 Client Secret 키를 확인하고 복사해 둡니다. (이 키는 외부로 유출되면 안 됩니다.)
그리고 해당 사용량은 내 애플리케이션에서 확인할 수 있습니다.
그리고 Gemini 등의 툴을 통해서 API 검색 툴을 만들어 달라고 하면 되는데요.
import os
import sys
import urllib.request
import json
import pandas as pd
# ==========================================
# [필수 변경] 네이버 개발자 센터에서 발급받은 정보 입력
# ==========================================
CLIENT_ID = "YOUR_CLIENT_ID_HERE"
CLIENT_SECRET = "YOUR_CLIENT_SECRET_HERE"
def search_naver_blog(query, display_count=10):
"""
네이버 블로그 검색 API를 호출하여 결과를 반환하는 함수
"""
encText = urllib.parse.quote(query)
# 블로그 검색 URL (json 형식)
url = f"https://openapi.naver.com/v1/search/blog.json?query={encText}&display={display_count}"
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", CLIENT_ID)
request.add_header("X-Naver-Client-Secret", CLIENT_SECRET)
try:
response = urllib.request.urlopen(request)
rescode = response.getcode()
if rescode == 200:
response_body = response.read()
# 바이트 데이터를 텍스트 및 JSON 객체로 변환
data = json.loads(response_body.decode('utf-8'))
return data.get('items', [])
else:
print(f"Error Code: {rescode}")
return None
except Exception as e:
print(f"오류가 발생했습니다: {e}")
return None
def save_to_csv(items, filename="search_result.csv"):
"""
검색 결과를 가공하여 CSV 파일로 저장하는 함수
"""
if not items:
print("저장할 데이터가 없습니다.")
return
parsed_list = []
for item in items:
# HTML 태그 제거 및 텍스트 정제
title = item['title'].replace('<b>', '').replace('</b>', '')
description = item['description'].replace('<b>', '').replace('</b>', '')
parsed_list.append({
"제목": title,
"블로그 링크": item['link'],
"설명": description,
"블로거 이름": item['bloggername'],
"작성일": item['postdate']
})
# 데이터프레임 생성 및 CSV 저장 (인코딩은 엑셀 호환을 위해 utf-8-sig 사용)
df = pd.DataFrame(parsed_list)
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"성공적으로 '{filename}' 파일로 저장되었습니다.")
# ==========================================
# 프로그램 실행부
# ==========================================
if __name__ == "__main__":
if CLIENT_ID == "YOUR_CLIENT_ID_HERE" or CLIENT_SECRET == "YOUR_CLIENT_SECRET_HERE":
print("[경고] 발급받은 네이버 Client ID와 Client Secret을 코드에 입력해 주세요.")
sys.exit()
search_keyword = input("검색할 키워드를 입력하세요: ")
try:
count = int(input("가져올 결과 개수를 입력하세요 (최대 100개): "))
except ValueError:
count = 10
print(f"\n'{search_keyword}' 검색 중...")
search_results = search_naver_blog(search_keyword, display_count=count)
if search_results:
save_to_csv(search_results, filename=f"naver_blog_{search_keyword}.csv")
else:
print("검색 결과를 가져오지 못했습니다.")